Paper: StreamKV: Streaming Video Question-Answering with Segment-based KV Cache Retrieval and Compression
Code: sou1p0wer/StreamKV
Background
Streaming video question-answering (StreamingVQA) requires a model to continuously process incoming video, preserve useful historical context, and answer questions online with low latency.
ReKV showed that video QA can be reformulated as retrieve relevant KV caches first, then answer with the retrieved KV. But it still has several weaknesses:
- It uses uniform segmentation, which may cut through semantic boundaries.
- It keeps essentially the whole historical visual context, so memory usage is still large.
- Its retrieval strategy is not flexible enough, especially when the useful information is distributed differently across layers.
Core Idea
StreamKV extends the ReKV line in two directions at the same time:
- better segmentation / retrieval: partition the stream into semantic segments instead of fixed chunks, and preserve a summary vector for each segment;
- compression: compress KV caches immediately after each segment is encoded, so the system does not need to keep all past frame-level KV blocks.
The method is still training-free, so it can be added to an existing Video-LLM without additional model training.
Method
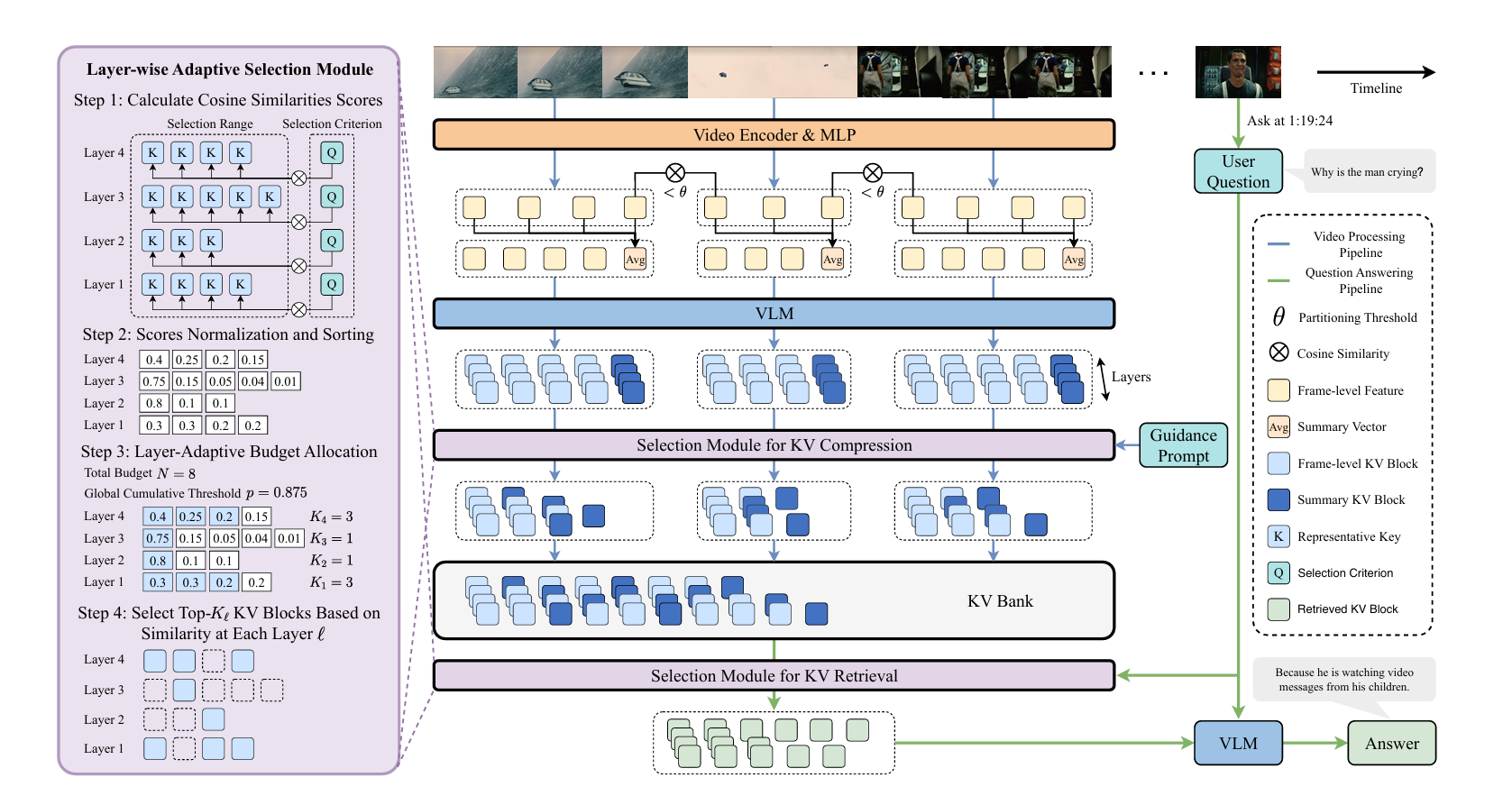
1. Semantic Segment Partitioning
Instead of dividing the stream uniformly, StreamKV detects semantic boundaries by computing the cosine similarity between adjacent frame embeddings.
- If similarity drops below a threshold, this indicates a likely semantic boundary.
- A minimum segment length is enforced to avoid over-fragmentation.
- A maximum segment length is also enforced; if a segment becomes too long, the method merges the most similar adjacent frames to keep the segment compact.
So each video is converted into a sequence of semantic segments, rather than fixed-size blocks.
2. Summary Vector for Each Segment
For every segment, StreamKV computes a summary vector by averaging frame-level features.
This summary vector serves two purposes:
- it preserves segment-level semantics even if many frame-level KV blocks are later discarded;
- it provides a stable representation that helps downstream retrieval.
Importantly, the KV block produced from the summary vector is explicitly kept and is not compressed away.
3. Segment-based Sliding-window Encoding
Like ReKV, StreamKV still relies on sliding-window attention during online video encoding.
- The current segment and its summary vector are encoded together.
- A local window of previous KV caches is used as short-term context.
- The model produces frame-level KV blocks for the segment, and also a summary KV block from the summary vector.
- Only the frame-level KV blocks are candidates for later compression; the summary KV block is explicitly preserved.
So the pipeline becomes: segment → encode → compress → store.
4. Unified Layer-Adaptive KV Selection Module
This is really the key reusable component in StreamKV, and the paper applies it twice:
- once for compression
- once for retrieval
The paper formulates both tasks in the same abstract way:
- there is a selection range, namely a set of candidate representative key vectors;
- there is a selection criterion, namely a vector that says what we want to keep;
- there is a fixed total budget, namely how many KV entries can be selected overall.
Under this view:
- in compression, the criterion is the guidance prompt
- in retrieval, the criterion is the user question
The module then works in three steps.
Step 1: cosine similarity scoring
- For each transformer layer, compute the cosine similarity between every candidate representative key and the criterion vector.
- So each layer gets its own relevance score distribution.
Step 2: normalization and sorting
- Normalize the scores within each layer.
- Sort them from high to low, so each layer gets a priority list of candidates.
Step 3: layer-adaptive budget allocation
- Instead of giving every layer the same number of selected KV blocks, StreamKV allocates the budget adaptively across layers.
- The paper introduces a global threshold and solves it by binary search, so that the total number of selected KV blocks matches the desired budget.
- Intuitively, layers whose score distributions are more concentrated get a larger effective budget.
So the output of this module is:
- a set of selected indices for each layer
- with the global budget satisfied
- without forcing uniform selection across layers
This is the conceptual center of StreamKV. The later compression and retrieval stages are just two different ways to instantiate the same selection module.
5. KV Compression via Guidance Prompt
This is the first application of the unified selection module, and one of the main differences from ReKV.
In streaming settings, the user question is usually unknown at the time of encoding/compression, and multi-turn dialogue may happen later. So compression should not depend on a specific question.
To solve this, StreamKV introduces a guidance prompt that tries to preserve the most important semantic content in a segment, such as:
- salient entities;
- key events and actions;
- temporal / causal relations;
- scene changes and contextual cues;
- important factual or numerical details.
Now the unified selection module is instantiated as follows:
- selection range: the representative keys of the current segment’s frame-level KV blocks
- selection criterion: the guidance-prompt vector
- budget: determined by the target compression ratio
The module selects the most informative frame-level KV blocks under that budget.
After selection:
- the chosen frame-level KV blocks are kept;
- the discarded ones are removed;
- the summary KV block is always retained and added to the KV Bank together with the compressed frame-level KV blocks.
So compression in StreamKV is not a separate heuristic. It is exactly the unified selection module, with a question-agnostic semantic criterion.
6. Retrieval and Question Answering
This is the second application of the same unified selection module.
When a question arrives, StreamKV:
- encodes the question into query vectors;
- uses those question vectors as the selection criterion;
- uses the representative keys stored in the KV Bank as the selection range;
- applies the same layer-adaptive selection module under a retrieval budget;
- retrieves the selected KV blocks from the KV Bank;
- uses the retrieved KV as context for answer generation.
This preserves the ReKV-style decoupling between video encoding and question answering, but with better memory efficiency and better retrieval quality.
So from the paper’s perspective:
- compression = unified selection with a guidance prompt
- retrieval = unified selection with a user question
That is why the “Unified Layer-Adaptive KV Selection Module” should really be viewed as the central mechanism, not as a side detail after compression.
7. Position Encoding
The paper also points out that RoPE becomes problematic for long distances. So StreamKV uses different positional handling for the two stages:
- segment encoding: apply RoPE only within the local window;
- question answering: treat retrieved tokens as consecutive and use their relative positions, rather than their original absolute positions.
This is conceptually close to ReKV, but here it is integrated with semantic segmentation and compressed retrieval.
Remark: Same as ReKV, this may be more complicated in newer models
Experiments
Benchmark
The main benchmark in the paper is StreamingBench, which contains 18 subtasks across three categories:
- Real-Time Visual Understanding
- Omni-Source Understanding
- Contextual Understanding
Implementation Details
The paper uses LLaVA-OneVision-Qwen2-7B-OV as the backbone. Key settings include:
- 0.5 FPS streaming rate
- 15K local window size
- minimum / maximum segment length = 4 / 64 frames
- partition threshold = 0.99
- 8 retrieved frames for KV retrieval
- experiments run on NVIDIA H20 96GB GPUs with FP16
Main Results
Compared with ReKV on StreamingBench, StreamKV improves not only accuracy, but also memory usage and latency.
A few notable results:
- With 60% KV compression, StreamKV-7B reaches 58.9 overall, compared with 53.5 for ReKV-7B.
- Even with 90% compression, it still achieves 56.7 overall, which remains above ReKV.
- On the Clips Summarization (CS) subtask, StreamKV with 60% compression gets 87.7, a large gain over both ReKV and the base LLaVA-OV model.
The paper’s main message is that better segmentation + summary preservation + adaptive compression/retrieval works better than simply storing all KV caches and retrieving from fixed chunks.
Remark: ReKV doesn’t use this benchmark Remark: Do we truly need open-ended questions?
Ablations
The ablation studies are pretty clean and support the design choices.
Semantic Partitioning vs Uniform Partitioning
Semantic partitioning consistently outperforms uniform segmentation across compression ratios.
Interpretation:
- compression is more reliable when the retained unit is a semantic segment rather than an arbitrary fixed block;
- this better preserves contextual continuity.
Effect of the Summary Vector
Keeping the segment summary vector always helps.
This suggests that the summary KV block really does preserve important segment-level information, especially under aggressive compression.
Effect of Layer-Adaptive Selection
Using the adaptive strategy for both compression and retrieval gives the best results. Even applying it to only one of the two stages is already better than a fully uniform budget.
Number of Retrieved Frames
Interestingly, StreamKV performs worse when retrieving too many frames. The paper’s explanation is that once retrieval is precise enough, additional frames mostly add irrelevant context and hurt QA.
This is the opposite of ReKV, where retrieving more frames may be necessary because retrieval precision is lower.
My Takeaways
The semantic chunnking is interesting. I think there are many other papers did so. It’s a very simple approach.
The guidance-prompt design is also interesting. It avoids depending on the future user question, which is exactly the right constraint in a real streaming setting.
Another useful point is that StreamKV unifies compression and retrieval into the same layer-adaptive selection framework. That makes the system conceptually cleaner and probably easier to extend.
Limitations / Open Questions
- The method is still built on sliding-window encoding, so long-range information outside the local window is only preserved through stored KV blocks and summaries. This may affect the ability of models.
- The guidance prompt is hand-designed; its quality may affect what semantics survive compression.
- The paper mainly evaluates on StreamingBench; it would be useful to see broader validation on other streaming or open-ended benchmarks.
- It is still not obvious how well this design transfers to newer VLMs with more complicated positional / multimodal tokenization schemes.